- Published on
Kinesis Data Streams Overview
- Authors
- Name
- jonathan Bradbury
What is AWS Kinesis Data Streams
AWS Kinesis is a service that let's you process and analyze streaming data in real-time.
Putting Data
Shards and Partition Key
Kinesis partition keys are used to map incoming data to a specific shard. It is not the same as the shard id. If you have a stream with 4 shards, and you use partitionKey = 1, the data will end up on shard 3. This is because an "MD5 hash function is used to map partition keys to 128-bit integer values" (https://docs.aws.amazon.com/streams/latest/dev/key-concepts.html)
You want data to be distributed across all shards to avoid hot shards. Each shard has a limit of 1mb/s ingress and 2mb/s egress. To increase the rate of ingress to your stream, you add more shards, but you need to be aware of the partition keys being used to send data. If all data uses the same partition key, it wont matter how many shards your stream has.
You can use a uuid as the partition key, if you don't care about sorting. If you do care about sorting, you'll want to make sure that data from a specific producer uses the same partition key. Kinesis will store data in order of time received in a shard. If you use random partition keys, your data will end up on random shards so you lose ordering.
Take a stream with 4 shards
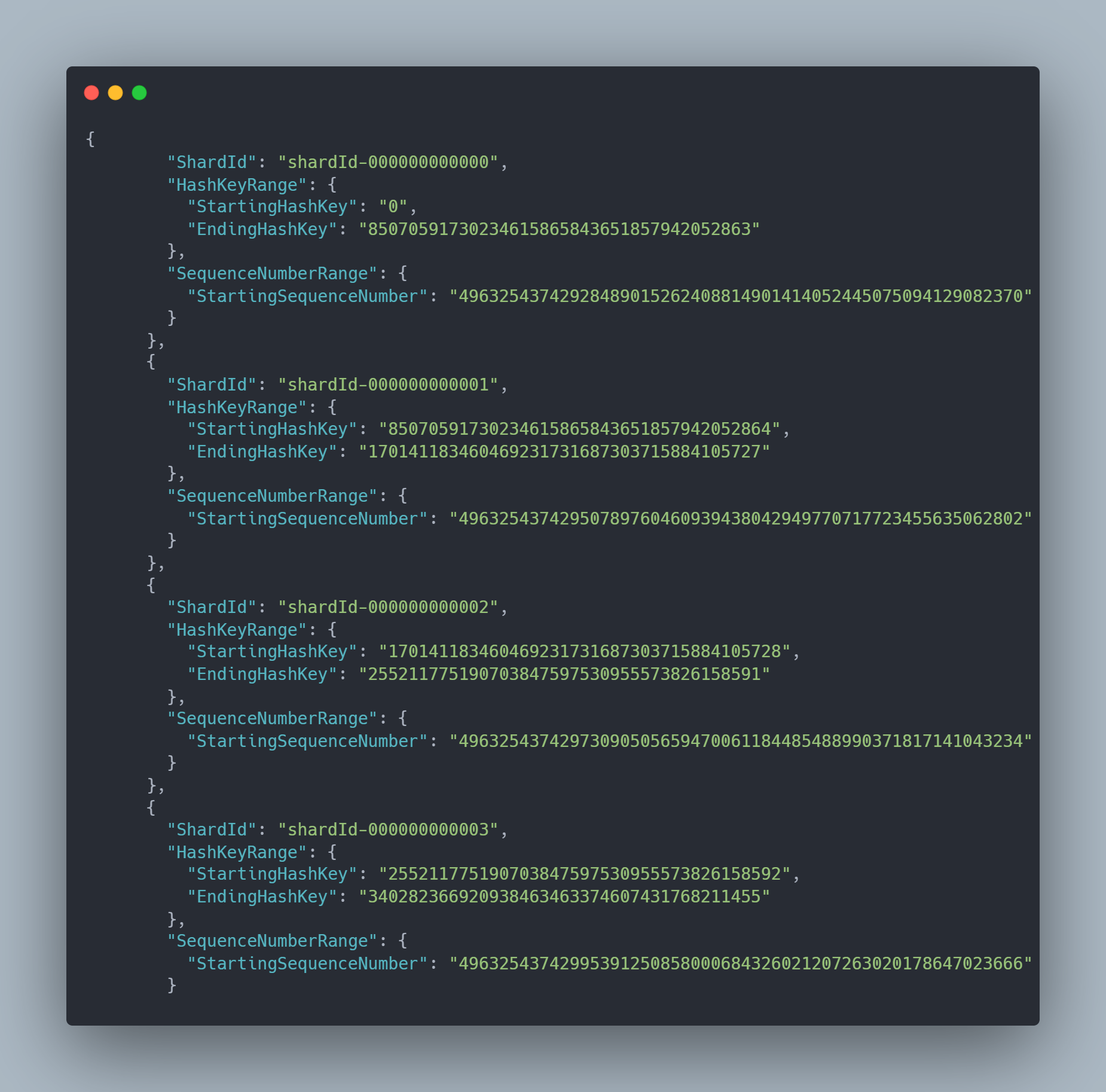
Notice that each shard has a starting hash key and ending hash key. This corresponds to where your partition key will put data
For example let's look at the value of a partitionKey of "1"
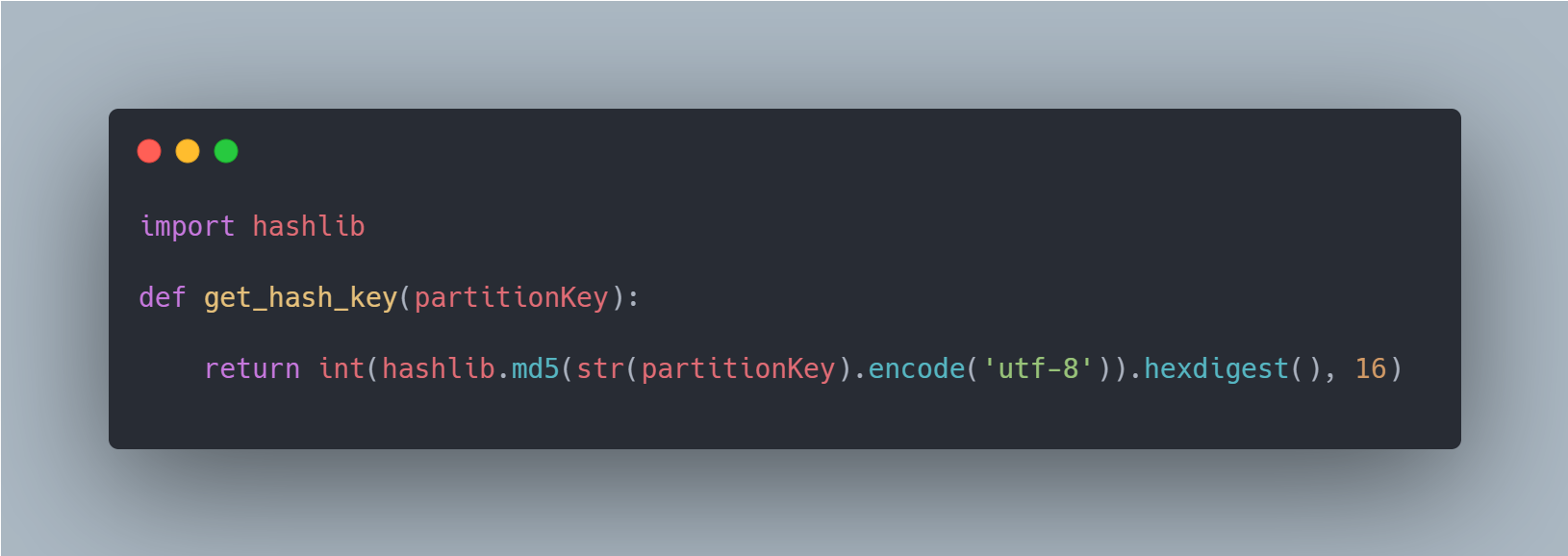
hash_key = 261578874264819908609102035485573088411
This number falls between 255211775190703847597530955573826158592 and 340282366920938463463374607431768211455 which places it on ShardId 3
PartitionKey 'blahblahblah' would result in a HashKey of 94261228062202320408097075168134233129, which ends up on ShardId 1
If you add more shards, the StartingHashKey and EndingHashKey ranges will shrink to allow for more ranges. Let's add 4 more shards (new total 8) and check out the ranges.
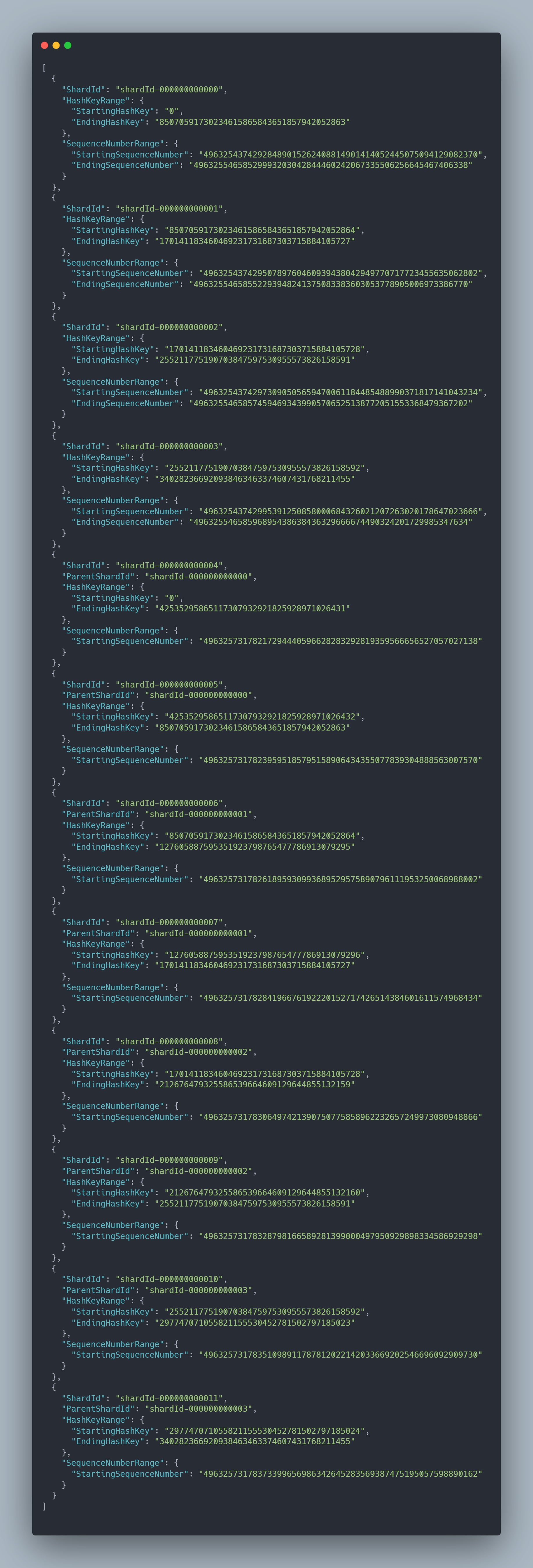
You might notice we went from 4 to 12 shards. This is because the parent shards, or pre existing shards, were split to make room for the new shards.
4 parents 8 children. The parent shards move into a closed state which allows you to continue to pull data from them, however data that would fall into the parents range will now be sent to the child shard.
Optionally you can use an ExplictHashKey to put data on a shard it wouldn't otherwise end up on.
Example
let's say you had 7000 restaurants which have a six digit zero padded restaurant id. You want to use that ID as the partition key, how would that data be distributed in this 8 shard scenario?
{
"0": 895,
"1": 867,
"2": 892,
"3": 845,
"4": 894,
"5": 851,
"6": 867,
"7": 889
}
This is a pretty good result. It distributes the data pretty evenly between shards.
let's take this same example with different shard amounts
4 shards, still pretty even
{
"0": 1762,
"1": 1737,
"2": 1745,
"3": 1756
}
16 shards, This looks like a pretty good PartitionKey strategy for our stream
{
"0": 467,
"1": 428,
"2": 417,
"3": 450,
"4": 450,
"5": 442,
"6": 421,
"7": 424,
"8": 457,
"9": 437,
"10": 433,
"11": 418,
"12": 452,
"13": 415,
"14": 462,
"15": 427,
}
Managed Kinesis Streams
You don't have to worry about adding new shards as your data ingestion goes up if you don't want to. Kinesis offers on demand streams that will auto scale based on the data coming in.
When you first create an on demand stream it appears that you get 4 shards by default. You can switch between "On-demand" and "Provisioned". So if you expect a huge influx of traffic you may want to switch to provisioned and allocate a bunch of shards beforehand. This will avoid any throttling errors you might see with on-demand as you wait for it to provision more shards for you. Afterwards you can always switch back to On-demand when you expect your traffic to be back to normal levels.
Example on demand describe stream
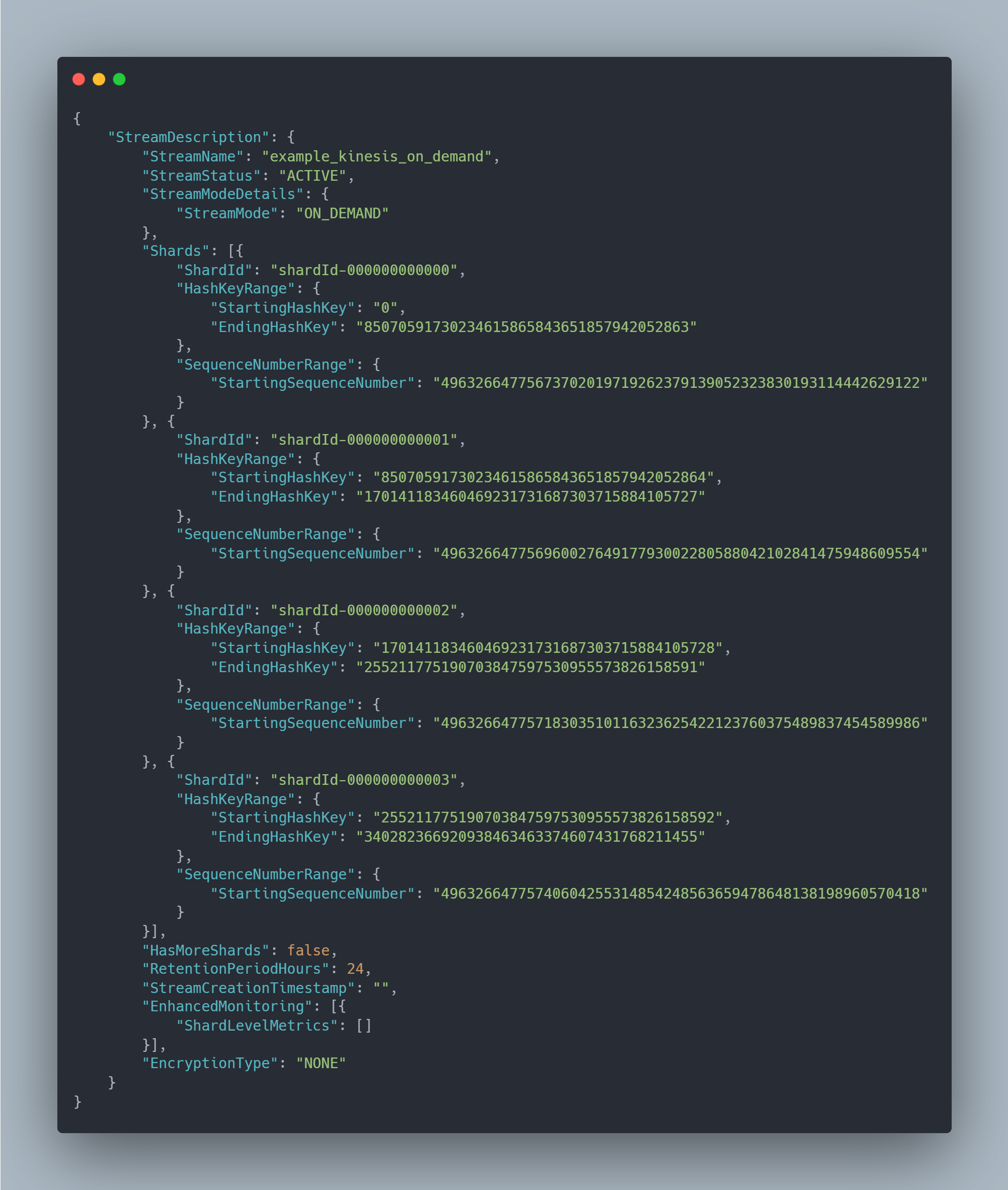
Getting Data
How it works
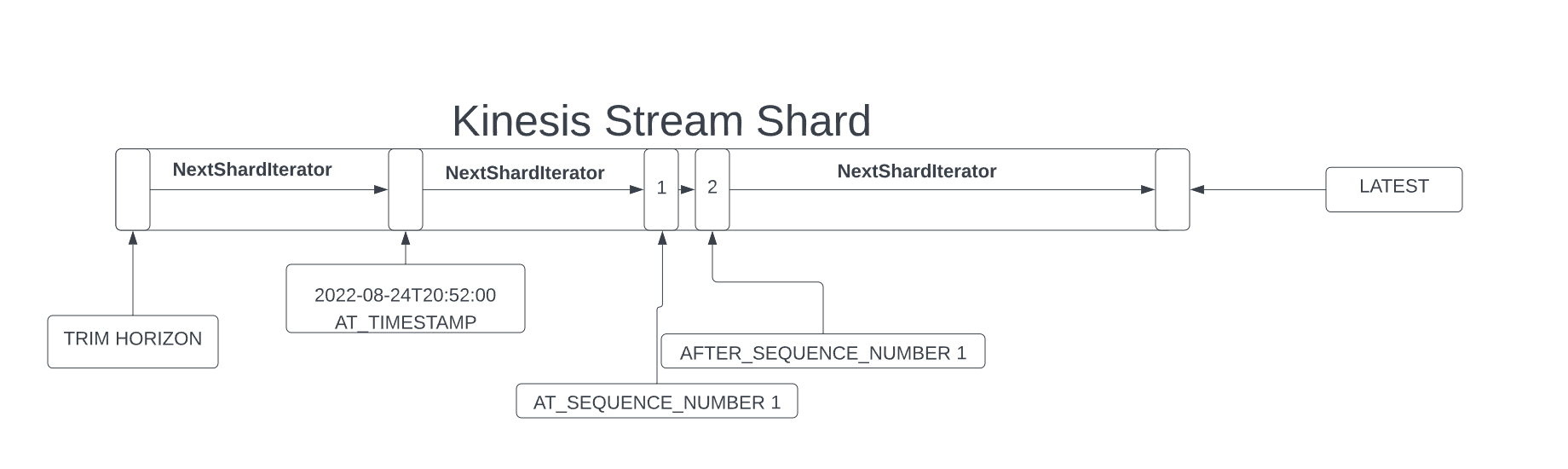
Getting your data out of a kinesis stream comes in 5 flavors. (https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/kinesis.html#Kinesis.Client.get_shard_iterator)
AT_SEQUENCE_NUMBER - "Start reading from the position denoted by a specific sequence number, provided in the value StartingSequenceNumber."
AFTER_SEQUENCE_NUMBER - "Start reading right after the position denoted by a specific sequence number, provided in the value StartingSequenceNumber."
AT_TIMESTAMP - "Start reading from the position denoted by a specific time stamp, provided in the value Timestamp."
TRIM_HORIZON - "Start reading at the last untrimmed record in the shard in the system, which is the oldest data record in the shard."
LATEST - "Start reading just after the most recent record in the shard, so that you always read the most recent data in the shard."
You pick a position in the stream with one of these methods as your starting point. Every get_records call you make from that starting point will return a NextShardIterator value that you use in subsequent calls to paginate over the data in the stream.
One thing I've noticed is that TRIM_HORIZON might sound like it starts at the place where the oldest record lives, but that's not the case. It might just be that I didn't have enough records in my stream, but I noticed that it would return empty Records arrays. I kept polling data using NextShardIterator and eventually I found my starting data.
I've also noticed that if you use LATEST you need to get the shard iterator before you start sending data, otherwise you will start at a place after where your data lives.
In my head I like to picture it like this
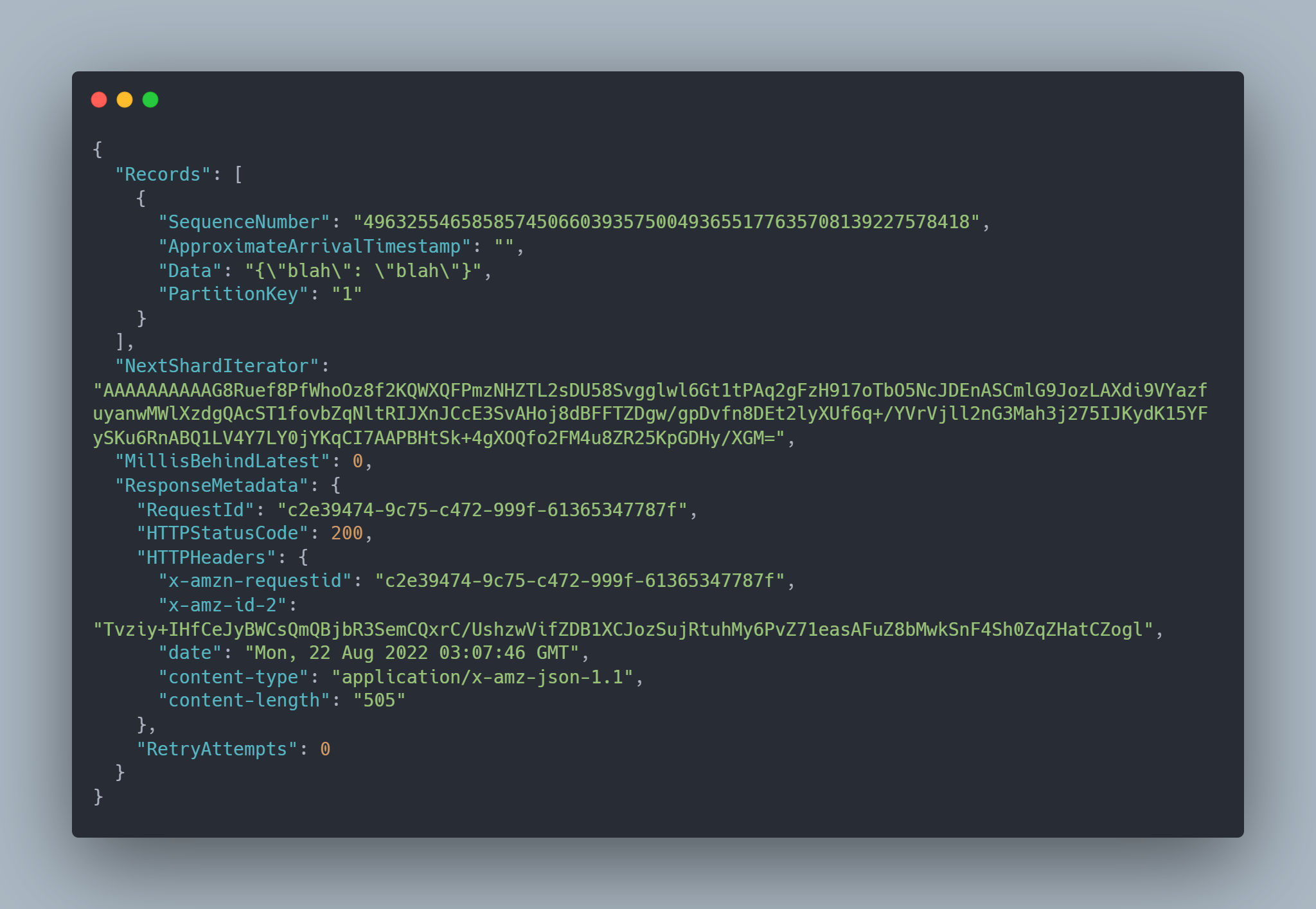
Kinesis Response Record Example
Reading data from Kinesis streams in AWS
There are a few ways you can read data from streams.
- AWS Lambda
- AWS Firehose
- AWS Kinesis Data Analytics
- Kinesis Client Library
The first 3 options are services that AWS offers, the last one is an SDK you can use to pull data from wherever you want.
Getting data with AWS Lambda
You can integrate with a kinesis stream via an event source. In cloudformation this would be
Type: AWS::Lambda::EventSourceMapping
You get several options when polling data from kinesis, the noteworthy ones are
BatchSize - How many records you will wait to build up passed your Starting Position before kinesis will invoke your lambda with said records. If you pull LATEST and set BatchSize to 100, Kinesis will wait until there are 100 records in the stream to invoke your lambda. This is great for saving lambda invocations.
BatchWindow - The maximum amount of time you wait for records in your stream. If you set BatchSize to 100 and Maximum wait to 60 seconds. If only 50 records come in during that minute, your lambda is still invoked thanks to the BatchWindow.
BisectBatchOnFunctionError - If your lambda fails to process a record in the stream, you can tell kinesis to bisect the batch and invoke the lambda again, this will eventually reduce until only the troubled record is left. You can dump that record into an SQS queue for later analysis.
ParallelizationFactor - How many lambdas you want to process a shard at once. If your stream has 1 shard, you can process it with 1 or 10 lambdas to increase throughput. If you kinesis stream has 100 shards and you sent ParallelizationFactor to 10, you will be processing with 1000 lambdas at once.
Getting data with Kinesis Firehose
Firehose integrates directly with kinesis and allows you to easily transform data and then send it to other sources. I won't go into all the options available but you can see them here.
(https://docs.aws.amazon.com/firehose/latest/dev/create-destination.html)
One that I will mention is S3. You can transform your data with a lambda the firehose stream will use, the lambda returns the data to the firehose stream and the stream will save your data to S3.
You can configure the stream to use an AWS Glue Schema to save your data to S3 in parquet format. This is great if you want to use AWS Athena to query your data from S3. It is pretty cool to be able to use SQL queries to extract data from files living in an S3 bucket.
Analyzing Data Directly in the Kinesis Stream
You can create Applications that use Apache Flink to query data directly from Kinesis for real time analytics. This topic deserves its own dedicated blog post however I'll show an example.
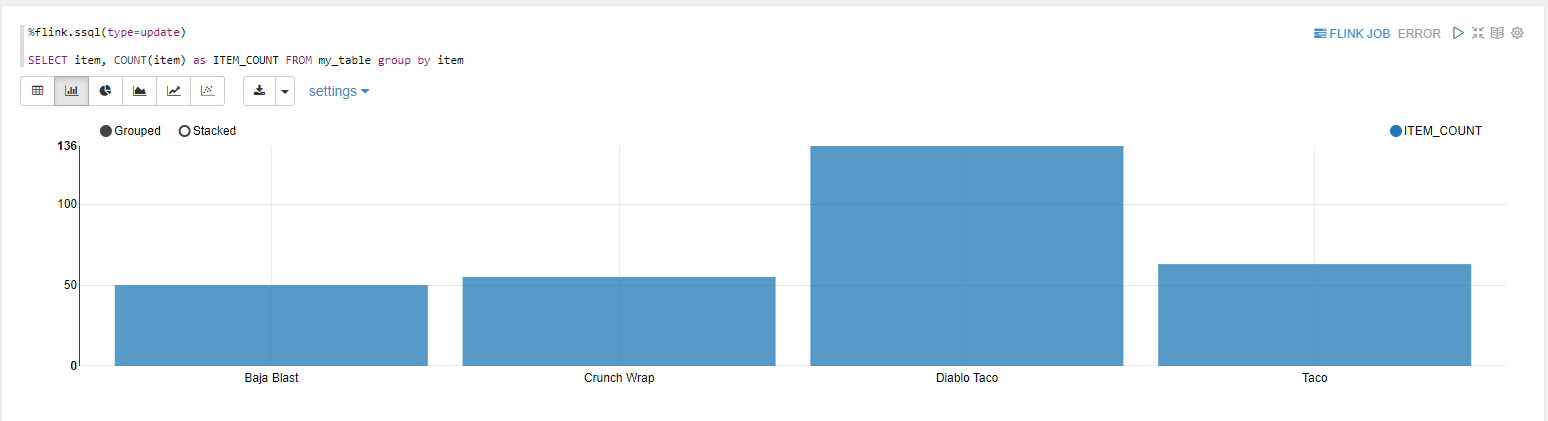
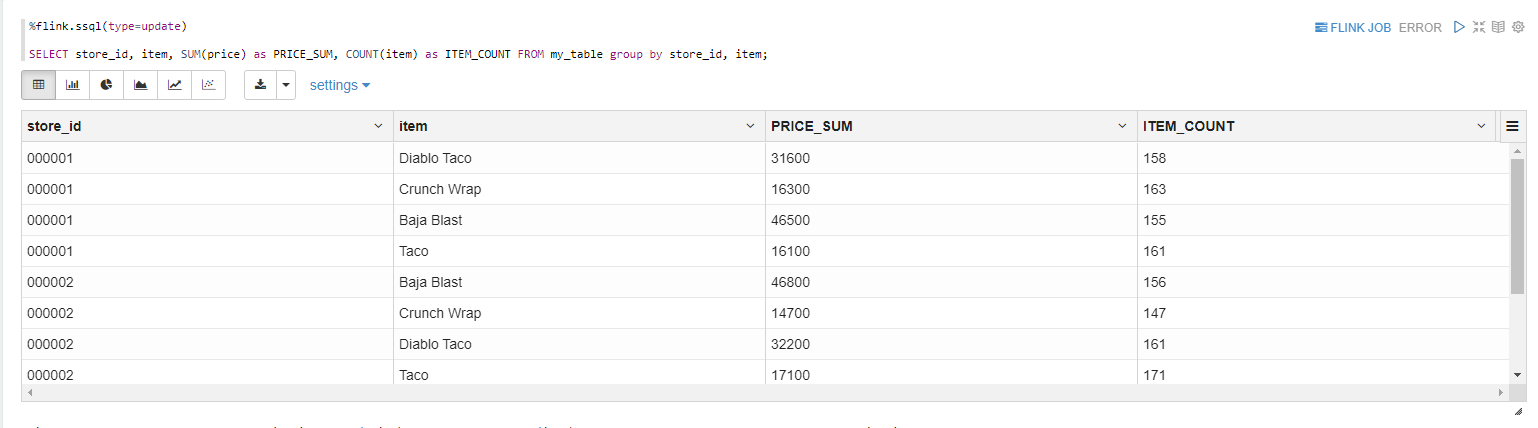
I used Kinesis Streaming Applications Studio to create a notebook which uses Apache Zepplin to query data from Kinesis. This is the most simple way to try out querying data from Kinesis.
On the left is a python script that's sending data to the kinesis stream in AWS. On the right you see my application querying the stream and displaying the quantity of items in the stream.
Results